
この記事は、Mastodon Advent Calendar 2017 6日目です。
Mastodonのサーバにおいてもっとも負荷の変動が激しいSidekiqは、よく確認したいものです。 ここでは、私のメインの監視基盤であるPrometheus+Grafanaで確認できる環境を組み立てます。
ご挨拶
初めまして。インターネットの片隅で、YUKIMOCHI Toot Hostという自宅回線・自宅設置の一人鯖、八月鯖という古閑鳥が鳴いている18禁ゲームインスタンス、無垢鯖(旧称、純真鯖)という検証向けインスタンスを運用している雪餅と申します。
もともと、サーバを立てて動かすのは好きでしたが、公開するコンテンツに困っていたことから、Mastodonに飛びつき、4/13よりおひとり様インスタンスをはじめ、なんだかんだで3つものインスタンスを目的もなく運用しています。(とはいえ、それぞれでDockerベースか否か、改造の有無などのA/Bテストを行うために構築している面もあります。)
今回は、そこそこの数のサーバを一括で監視するために利用しているprometheusでsidekiqの統計情報を収集する方法を記したいと思います。
イントロダクション
Mastodon における非同期処理の重要性
Mastodonは、投稿の配信などで非同期の処理を大量に発生させています。もし、この処理が捌き切れていないと・・・
- 自分の投稿がほかのインスタンスになかなか反映されない
- タイムラインがうまく流れない
などの問題をきたします。 問題解決するためには、
- サーバのスペックアップ
- Sidekiqサーバの並列化
- SidekiqプロセスのConcurrencyを高める
などの対応をとることになります。
既存の Sidekiq 監視の課題
さて、外部のインスタンスのフォロワーから「配信遅れてるみたいだよー」と言われたあなた(サーバ管理者)は、どうすればいいでしょうか。
まずは、Sidekiqのダッシュボードでジョブの消化状況を確認します。
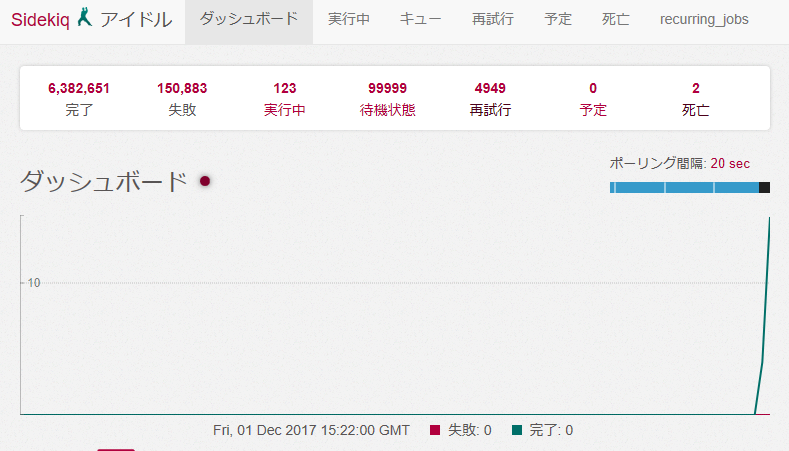
※ 画像はイメージです。
サーバスペックが十分にある環境であれば、上の図のように少ない実行数に大量の待機状態が溜まっているような状況になっているでしょう。(CPU使用率が高くなり動作が遅い場合は、別の話になります。)
この場合、その瞬間に管理者が行えることは特になく待機状態が捌かれるのを待つしかありません。 (CPU・メモリに余裕があったら docker-compose up -d --scale sidekiq=2 などを実行する手があります。) そして、最大の問題は今後の対応をとるための資料を何も提供してくれないことです。
ここで、Mastodon側に prome というgemを追加しジョブに関する情報を再利用可能な形で収集し、閲覧できるようにします。
今回の内容
- Prometheus と Grafana を Docker でさっくり構築する。
- Mastodon に prome を導入し、 prometheus 向けの metrics を配信する。
- Prometheus に Sidekiq のメトリックを収集させる。
- Grafana というダッシュボードツールを用いて、見やすいようにデータを加工して閲覧する。
Prometheus と Grafana を Docker でさっくり構築する。
これらはなに?
Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. (Overview | Prometheus)
Prometheus は、SoundCloudによって作られたプル型の監視・アラートシステムです。
プル型というのは、Mackerelなどのように監視対象が監視サーバにメトリックを送信するのではなく、監視対象がWebサーバのような形でメトリックを公開し、監視サーバがそれらにアクセスして情報を取得することを意味しています。 実際、Prometheusでは、 /metrics というURIでメトリックの記述されたテキストを取得する形を取っています。
Grafana
Grafana allows you to query, visualize, alert on and understand your metrics no matter where they are stored. Create, explore, and share dashboards with your team and foster a data driven culture. (Grafana – The open platform for analytics and monitoring)
Grafana は、様々なデータソースに存在するメトリックを取得し、ダッシュボードの作成を行うことができます。
Prometheus の標準の機能では、わかりやすくメトリックを閲覧・分析する機能が足りていません。したがって、 Grafana にそのデータを読み込ませることでこちら側でダッシュボードによる可視化を行います。
導入
今回の対象は、 docker-compose で運用される Mastodon のみの稼働しているサーバ上に動作させることを仮定します。
ホームディレクトリにて、
git clone https://github.com/yukimochi/prometheus_docker.git
cd prometheus_docker
chown 65534:65534 ./prometheusMastodonとgrafanaのポートが競合するため、docker-compose.yml の grafanaサービスのポートを 3000:3000 から 3100:3000 などに変更します。
grafana:
restart: always
image: grafana/grafana
ports:
- "3100:3000"
volumes:
- ./grafana:/var/lib/grafanadocker-compose up -dこれで、prometheusは、9090ポート、grafanaは、3000ポート(または変更先ポート)で待ち受けて起動します。 grafanaは、ID:admin PW:adminで入れるので、パスワードを変えておきます。
Mastodon に prome を導入し、 prometheus 向けの metrics を配信する。
Mastodon のディレクトリにある Gemfile と Gemfile.lock 加えて routes/config.rb を以下のコミットのように変更します。(注:このコミット自体は、master追従インスタンス向け)
(#2aa9391) Add prometheus metrics exporter support. – Github
この変更で、railsのメトリクスが3000ポート(Mastodon WebUIと共用)、sidekiqのメトリクスが9310ポートのそれぞれ /metricsで配信されるようになります。(認証はありません。秘匿したい場合、リバースプロキシなどで /metric へのアクセスを中継しないように設定をしてください。)
注意:非Dockerでsidekiqを一台のサーバ上に複数建てている場合はポート番号が重複します。環境変数 PROME_EXPOSE に各サービスごとのポート番号を与えてください。
Prometheus に Sidekiq のメトリックを収集させる。
つづいて、prometheus側でそれぞれのメトリックを取得するように設定を行います。 ~/prometheus_docker/prometheus/prometheus.yml の scrape_configs 以下に追加します。
- job_name: 'mastodon'
static_configs:
- targets: ['web:3000']
- job_name: 'mastodon-sidekiq'
static_configs:
- targets: ['sidekiq:9310','sidekiq-push:9310','sidekiq-pull:9310']※ web, sidekiq などは、dockerにおいてサービス名で名前解決をすることが前提です。普通の構成の場合は、 127.0.0.1:3000 などとする。
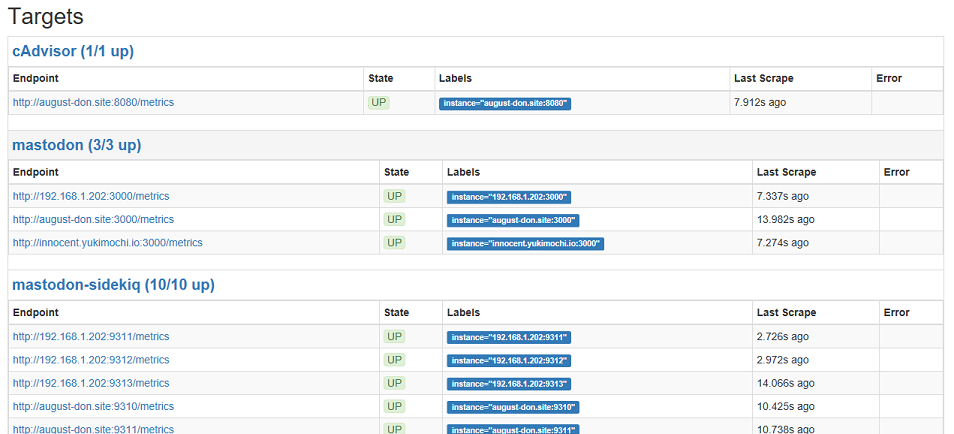
ここで、prometheusが起動しているサーバの9090ポートにHTTPでアクセスして、prometheusの動作を確認します。 タブの Status – Target から各監視対象の情報を一覧表示することできます。
以下は一例ですが、 State が UP になっていれば、正常にメトリックを取得しています。
Grafana というダッシュボードツールを用いて、見やすいようにデータを加工して閲覧する。
最後に Grafana で可視化を行います。冒頭の作業で変更したGrafanaサービスのポートにアクセスします。
データソースの追加
左上のメニューから Data Source を追加します。
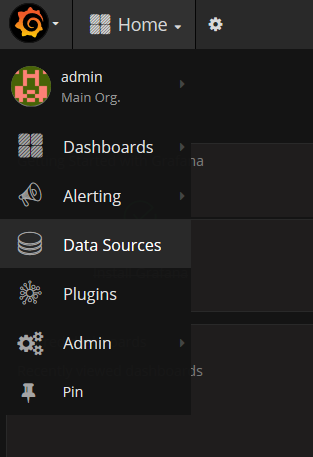
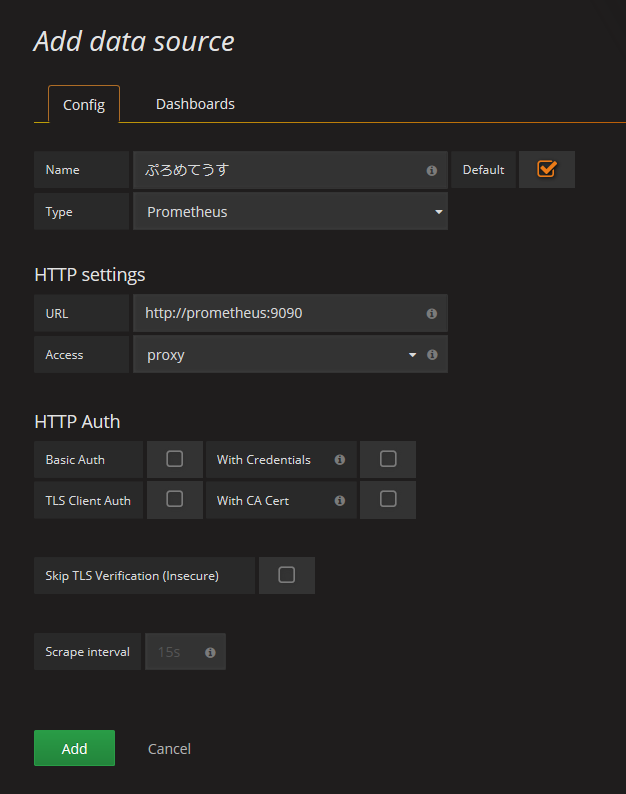
※ Access は、Proxy を選択するようにしてください。
ダッシュボードの作成
左上のメニューから Dashboard – New を選択します。
Graphなど、様々なものを各行に置くことができます。
Graphを配置して、 Edit を選択するとこのような設定画面が出てきます。
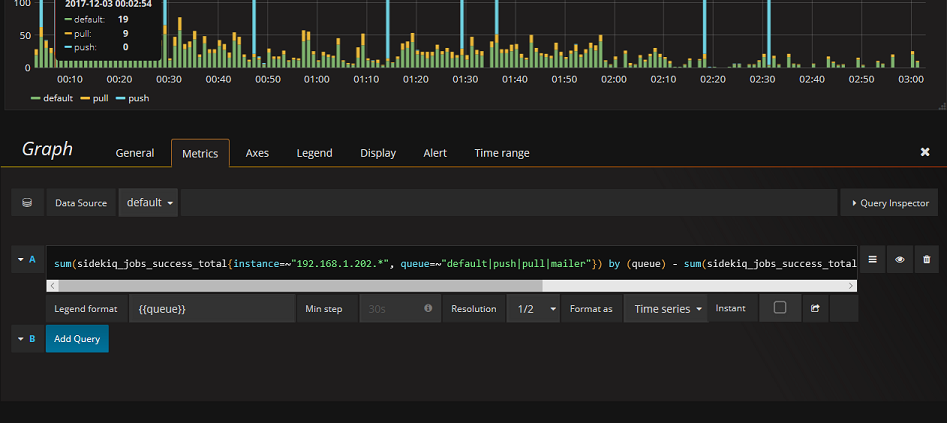
PromQL という文法に従い、グラフに表示するものを指定します。ここには、先に設定した prometheus のすべてのメトリックは入力補完が働きますので、いろいろ試してみるといいでしょう。
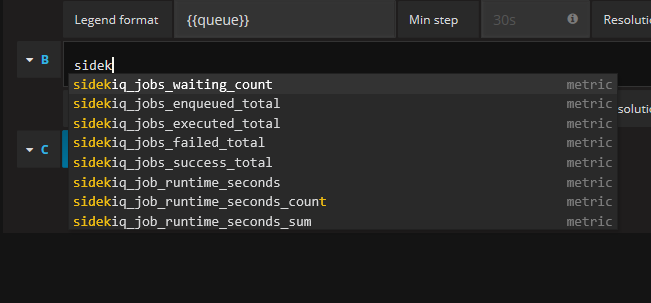
おすすめのクエリ紹介
ここでは、おすすめのPromQL文を紹介します。
- Sidekiqの実行中・失敗・待機中
| メトリック名 | 種別 | おすすめのPromQL文 | |
|---|---|---|---|
| 成功 | sidekiq_jobs_success_total | カウント | sum(sidekiq_jobs_success_total) by (queue) - sum(sidekiq_jobs_success_total offset 1m) by (queue) |
| 失敗 | sidekiq_jobs_failed_total | カウント | sum(sidekiq_jobs_failed_total) by (queue) - sum(sidekiq_jobs_failed_total offset 1m) by (queue) |
| 待機中 | sidekiq_jobs_waiting_count | カウント | sum(sidekiq_jobs_waiting_count) by (queue) |
成功と失敗は、累計処理ジョブ数の1分前との差をグラフに描画します。待機中は、各時点での積みあがっていたジョブ数を描画します。 これらのグラフは、いつどのようにジョブが積み上がり、どのように解消していったのかを観察するのに重要です。
以下は、ある時の私の管理するサーバの様子です。私のマスター通知BOTの投稿を一斉に削除するリクエストを飛ばし、待機中を無理やり積み上げました。
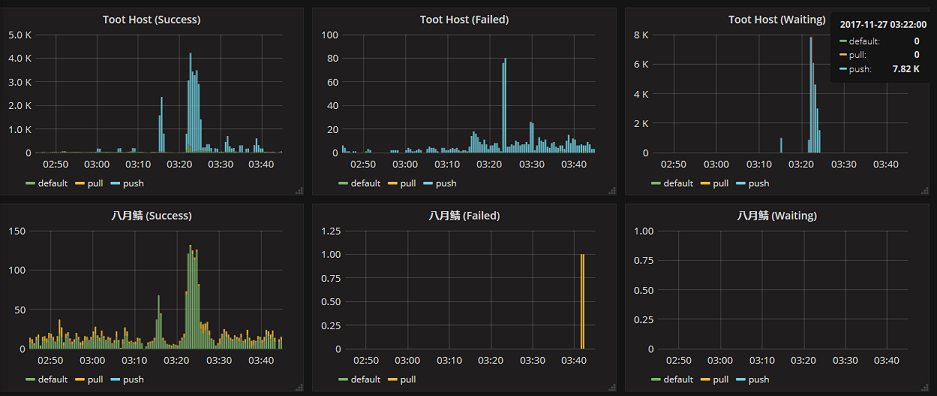
最大で、待機中は7.82Kに及び、30秒に1800件のペースで消化しました。(ついでに、その削除リクエストの影響で、八月鯖にdefaultのジョブが多く発生しているのは面白いです。) また、この環境においていえば、普段待機中はほぼ存在せず、快適な環境であることを改めて確認できました。
待機中にジョブがよく溜まる環境の場合は、それがどの種別のジョブで、1分当たりに何件処理できているのかを確認してみるとよいでしょう。node_exporterやcAdvisorのメトリックとあわせて、Sidekiqのconcurencyを上げたり、鯖の増強をするときの目標となる性能を見つけ出せるかもしれません。
さらに細かく見る
promeは、メトリックをキューとワーカでそれぞれ分離して提供しています。例えば、 sidekiq_jobs_success_total というメトリックは、以下のように分離された形で提供されます。
sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="ActivityPub::ProcessingWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="DistributionWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="FeedInsertWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="ProcessingWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="PushUpdateWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="Scheduler::FeedCleanupScheduler"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="Scheduler::IpCleanupScheduler"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="Scheduler::MediaCleanupScheduler"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="Scheduler::SubscriptionsScheduler"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="default",worker="Scheduler::UserCleanupScheduler"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="pull",worker="ActivityPub::PostUpgradeWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="pull",worker="LinkCrawlWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="pull",worker="RemoteProfileUpdateWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="pull",worker="ResolveRemoteAccountWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="pull",worker="ThreadResolveWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="push",worker="Pubsubhubbub::ConfirmationWorker"}sidekiq_jobs_success_total{job="mastodon-sidekiq",queue="push",worker="Pubsubhubbub::SubscribeWorker"}
先のおすすめPromQL文ではsum()式を利用してこれらの和を取って、queueごとに集計して表示するようにしていましたが、注目したいworkerがある場合は、それらに注視したグラフを作成してダッシュボードに置いておくことができます。
そのほかのメトリックを収集する
sidekiqが出力するメトリックは、上記の3つに加え sidekiq_job_runtime_seconds, sidekiq_jobs_enqueued_total, sidekiq_jobs_executed_total そして railsが出力するメトリックに rails_db_runtime_seconds, rails_request_duration_seconds, rails_requests_total, rails_view_runtime_seconds があります。
さらに、一般的な監視のソリューションで得られるような情報を得るには、別のエクスポーター(prometheus向けに /metrics でメトリクスを提供するソフトの総称)を入れる必要があります。
cAdvisor
Docker コンテナで Mastodon を運用しているならおすすめなのが、Google のコンテナ監視用のアプリケーション cAdvisor です。これ自体も Docker コンテナで動作し、1行の Docker コマンドで使い始めることができます。(これは、コンテナを動かしているホストの情報まで取得することができます。)
sudo docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latestcAdvisor は、8080ポートでメトリックが公開されますので、prometheus.ymlには、以下のように追記します。
- job_name: 'cAdvisor'
static_configs:
- targets: ['cadvisor:8080']node-exporter
Prometheus が公式に提供している、一般的なメトリックを公開することのできる Exporter です。ロードアベレージやストレージの空き容量などのメトリックも取得できます。9100ポートで公開されます。
これについては、多くの記事で使い方が紹介されていますので、以下の参考記事などを参照して導入してみるとよいでしょう。
参考記事
インフラ・サービス監視ツールの新顔「Prometheus」入門
おわりに
4月のインスタンス設立ブームから8か月経ち、いくつものインスタンスが財政や集客の都合で閉鎖していますが、私の周囲ではおひとり様や小規模クラスタのインスタンスブームが密かに再び始まっているような気がしています。
クラウドのサーバは気軽に利用できますが、趣味の範囲の予算では、性能は限定的です。末永く、安定的なインスタンスの運用を続けていくためには、サーバの実情とコストをしっかり見極めることが重要だと思います。
皆さんも、サーバと向き合いながら楽しい鯖缶ライフを送りましょう!
